cs224w-7-GNN2
GNN 层
Idea
1.将一组向量压缩成单个向量
2.两部处理,包括获得信息以及聚合
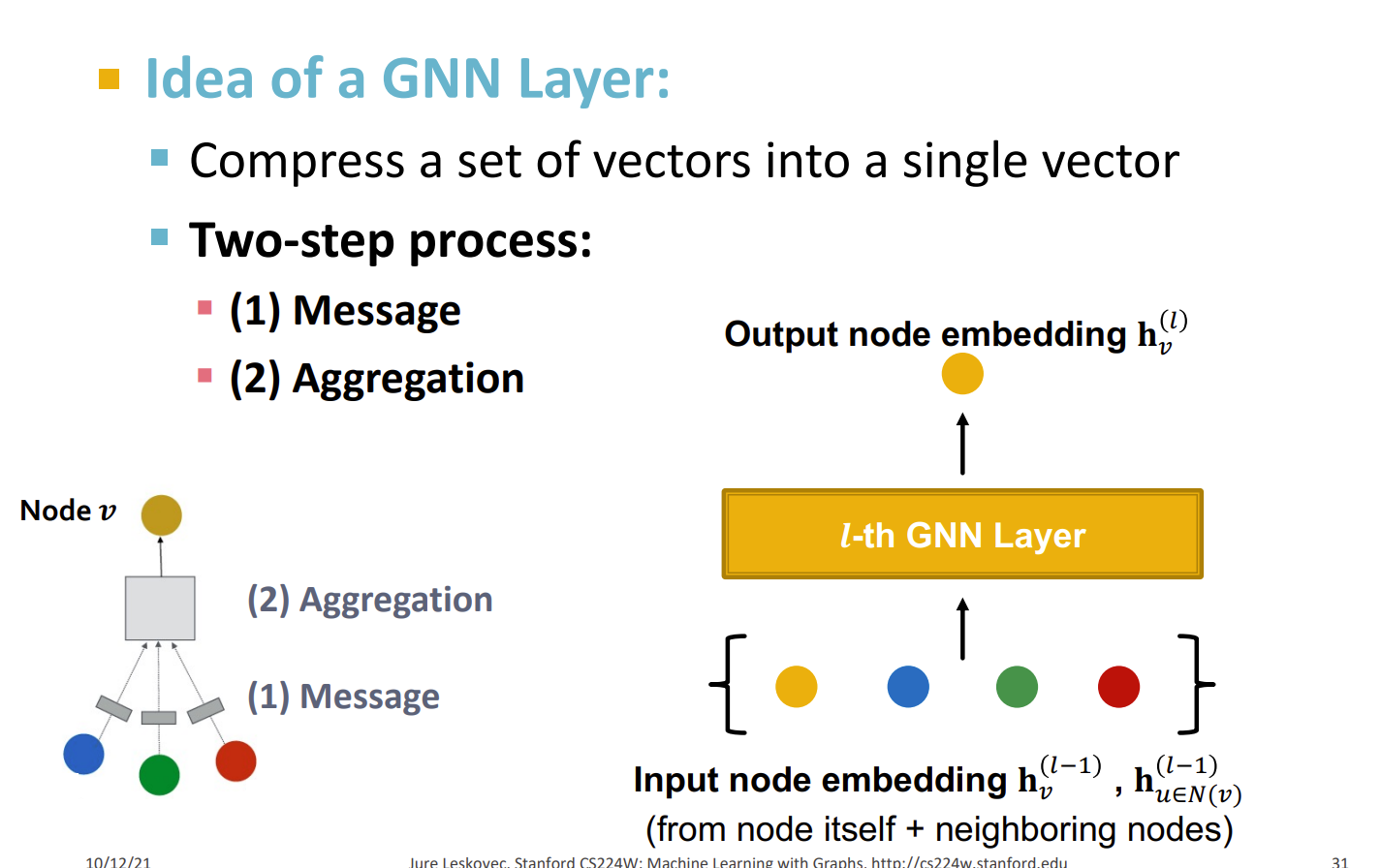
消息计算
MSG 可以是权重指数
消息聚合
AGG 函数可以是求和,平均值(mean),最大值函数等。
问题
与 并无直接关联
解决这个问题,可以加一个自环(考虑自身影响)
聚合函数即为
GCN
其中 是一个激活函数,可以是 等
与此同时,消息传递也要有一个正则化
GCN假设有自边,于是
GraphSAGE Graph SAmple and aggreGatE


\ell =
正则化

Graph Attention Networks (GAT)
图注意力网络,定义注意力权重
其中,如果 即为 GraphSAGE
但是不一定每个邻居的权重相等
定义注意系数
正则化 可以使用
于是

多头注意力
Multi-head attention(多头注意力):稳定注意力机制的学习过程

注意力机制的优点
1.Allows for (implicitly) specifying different importance values to different neighbors
允许(隐含地)为不同的邻居指定不同的重要性
2.Computationally efficient 计算效率高
3.Storage efficient 空间消耗小
Sparse matrix operations do not require more thanO(V+E) entries to be stored 稀疏矩阵不需要超过 的空间
Fixed number of parameters, irrespective of graph size
4.Localized:
Only attends over local network neighborhoods (不会翻译这个)
5.Inductive capability:
It is a shared edge-wise mechanism
It does not depend on the global graph structure
GNN 的应用

模块
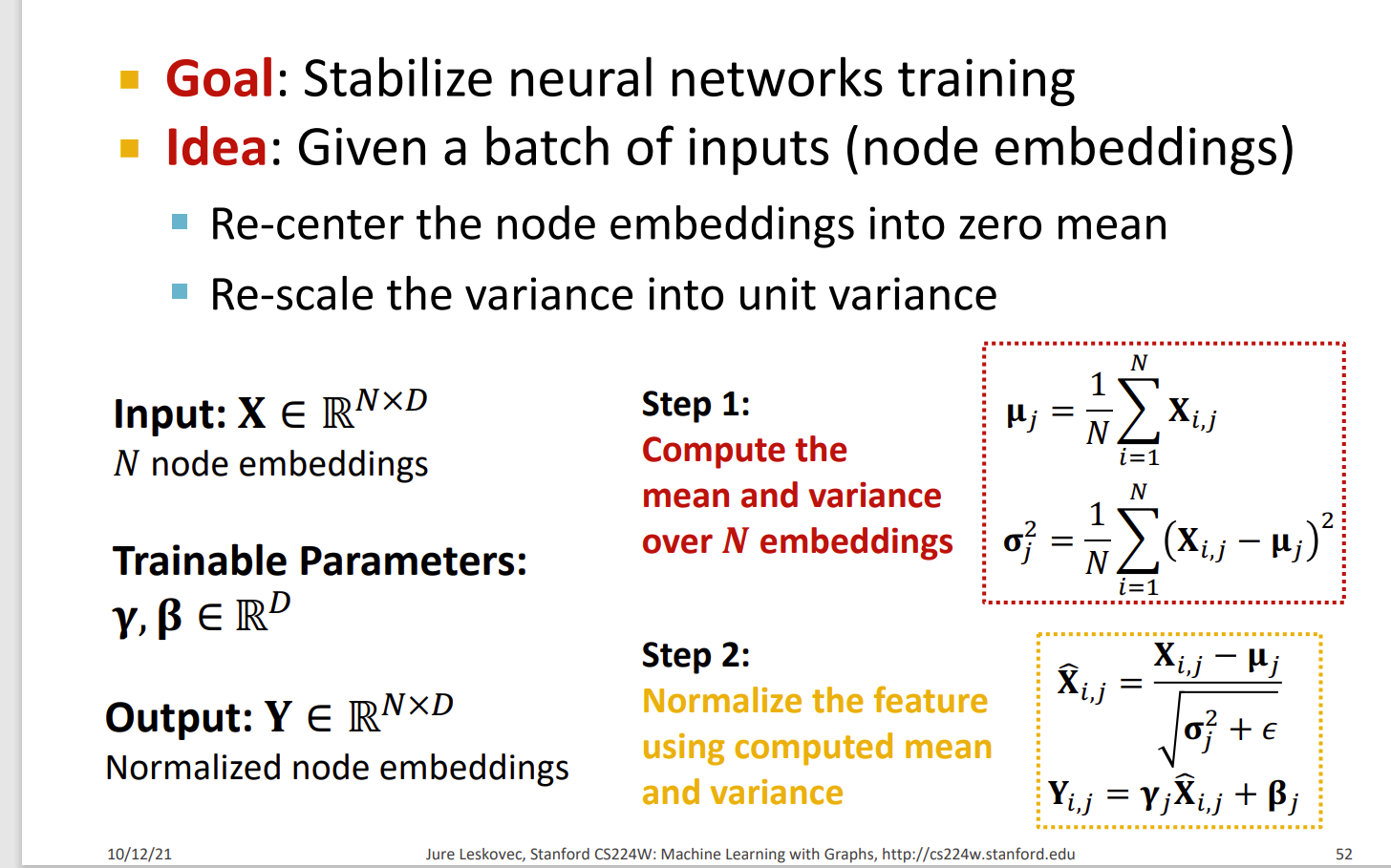
Batch Normalization
Stabilize neural network training
Given a batch of inputs (node embeddings),将节点嵌入重新居中为零均值,将方差重新缩放为单位方差
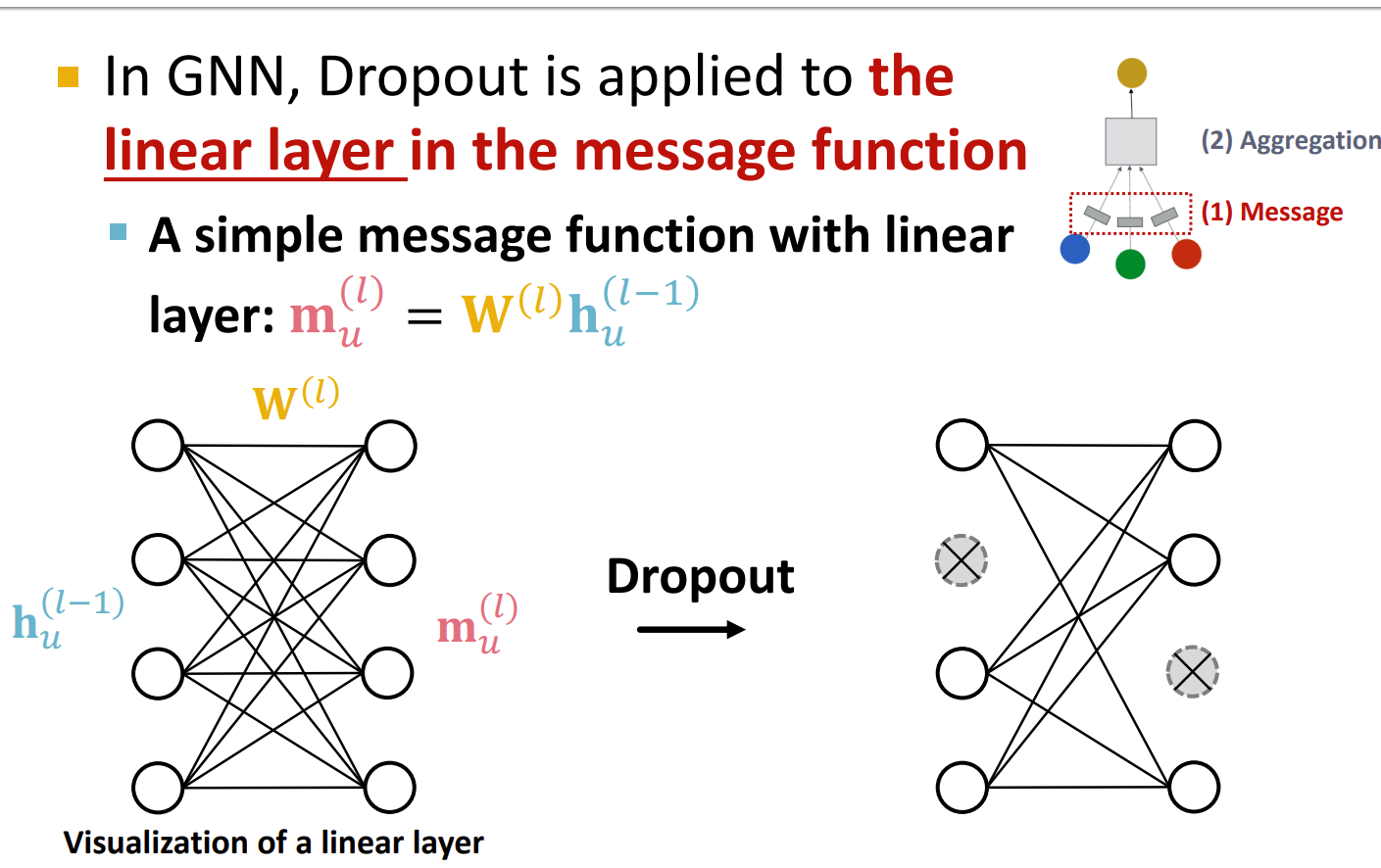
Dropout
按照某个概率丢弃某个部分的训练结果,防止过拟合
在训练期间:以某种概率 p,随机将神经元设置为零(关闭)
测试期间:使用所有神经元进行计算
Activation 激活函数

当然还有其他的激活函数
Attention/Gating
Control the importance of a message
以及其他的
堆叠 GNN 层
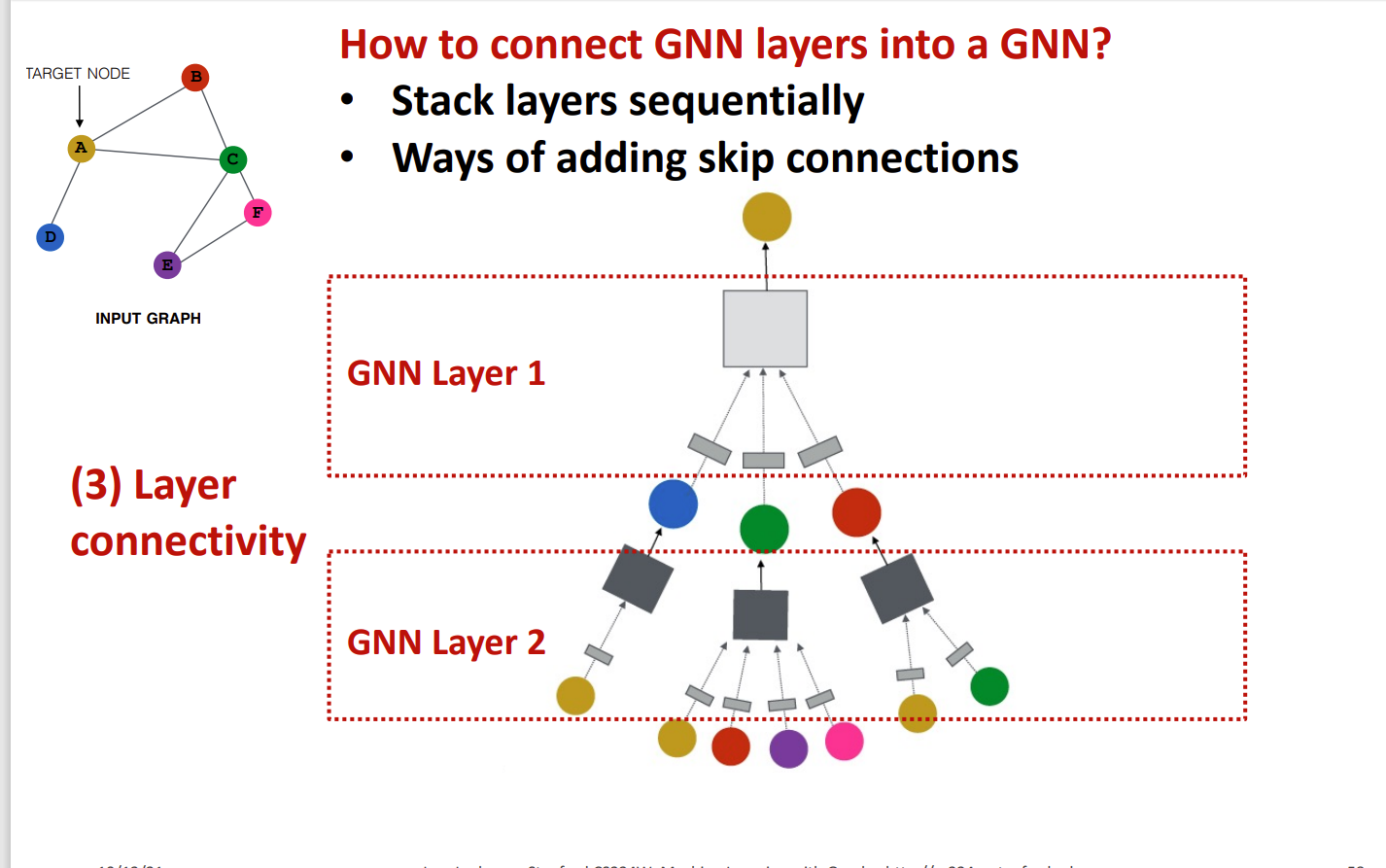
过多的GNN层会导致的一个缺点是 the over-smoothing problem 也就是最后这些嵌入会收敛到一个值
Receptive field
这个单词不知道中文意思。
the set of nodes that determine the embedding of a node of interest
The shared neighbors quickly grows when we increase the number of hops (num of GNN layers) 对叠层数越多,这个东西也就越大
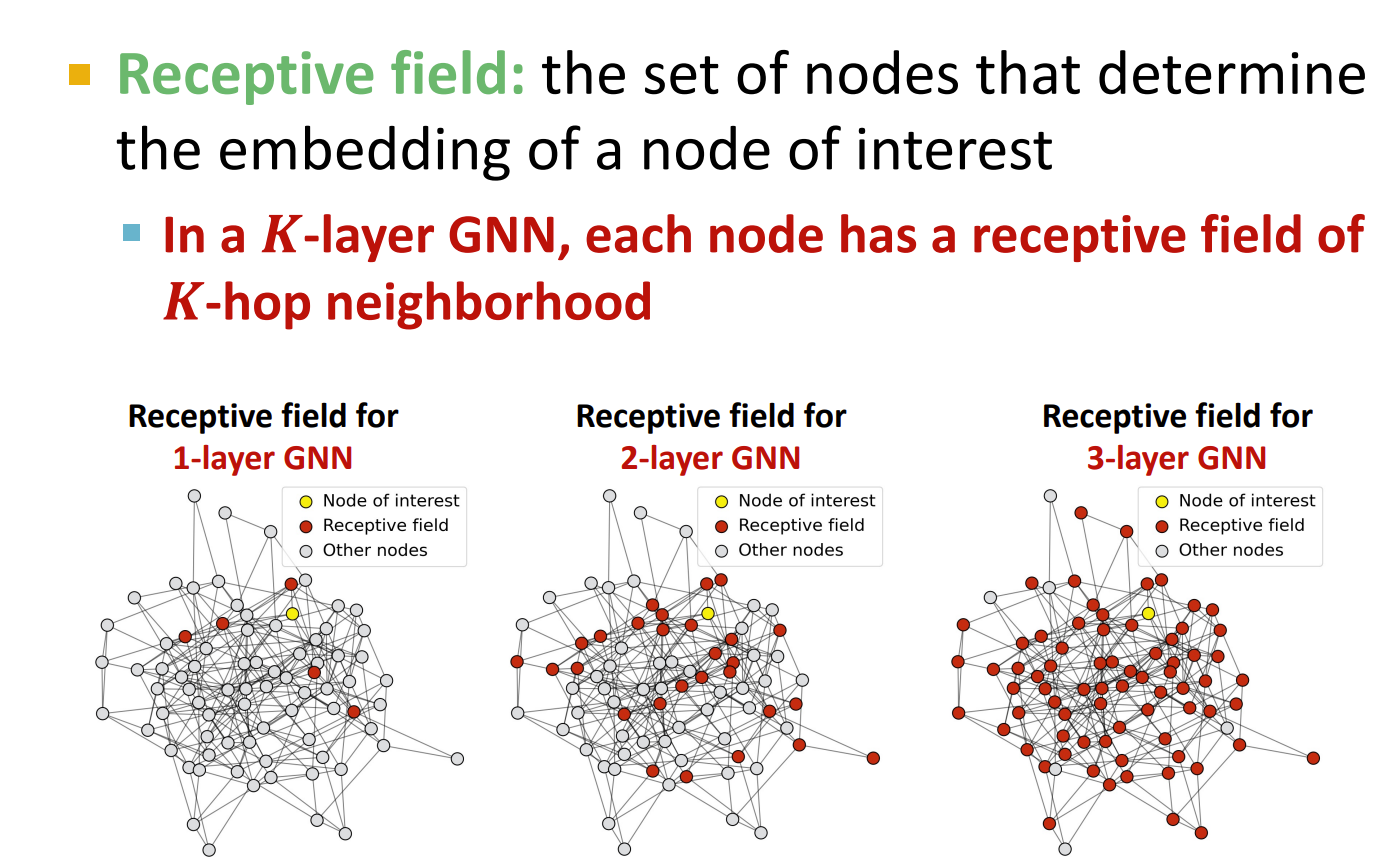
过平滑问题产生的原因:

处理 over-smooth 的方法
缩小GNN layers
根据刚才的讨论,显然地,图的结构很关键,并且 GNN 层数不能过多。
另外的一个问题则产生, GNN 能传递信息的能力也降低了。
有以下方法:
1.把聚合函数换成一个深度1神经网络
2.增加不传递消息的层数量

不缩小GNN layers
增加跨层的连接
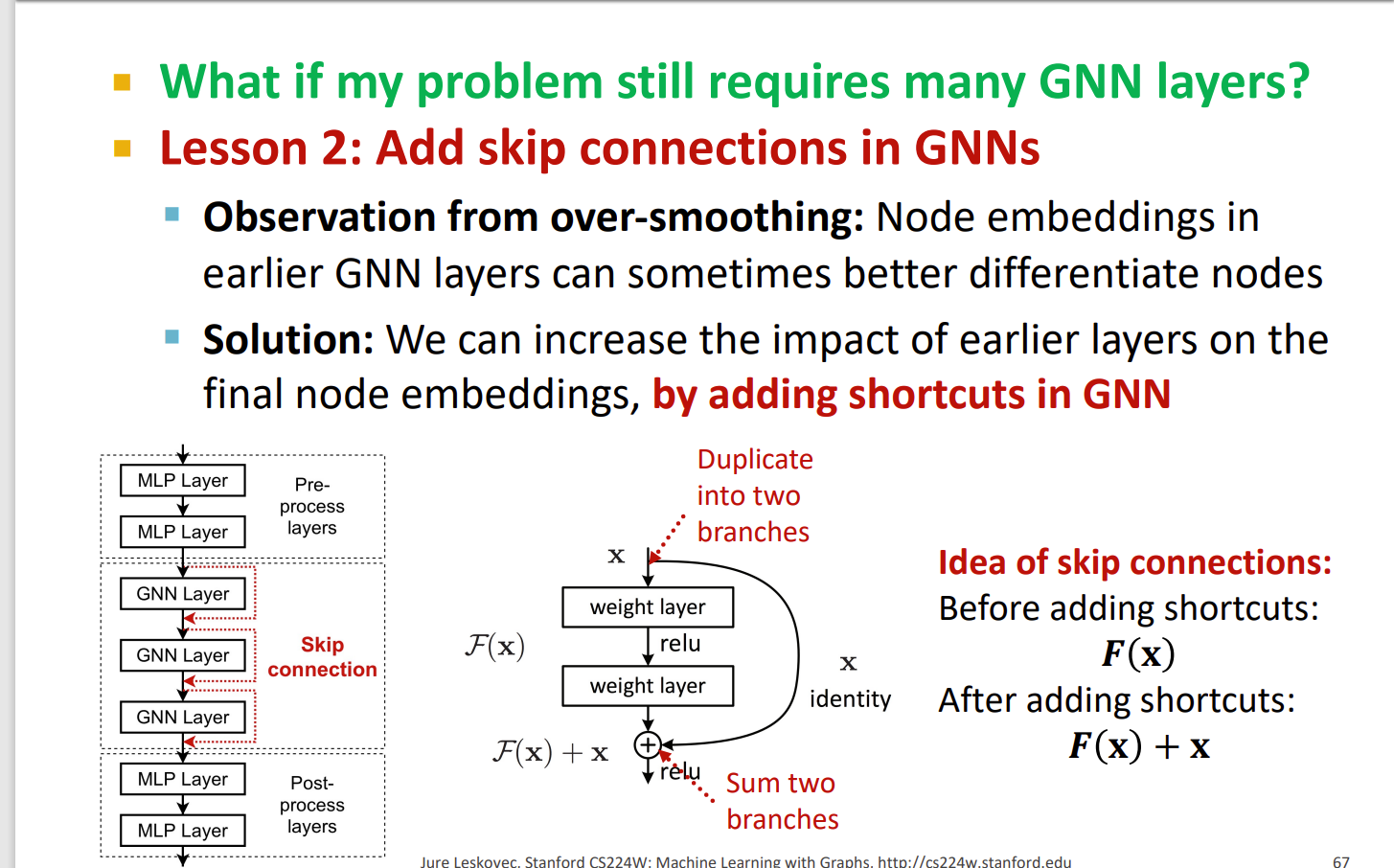
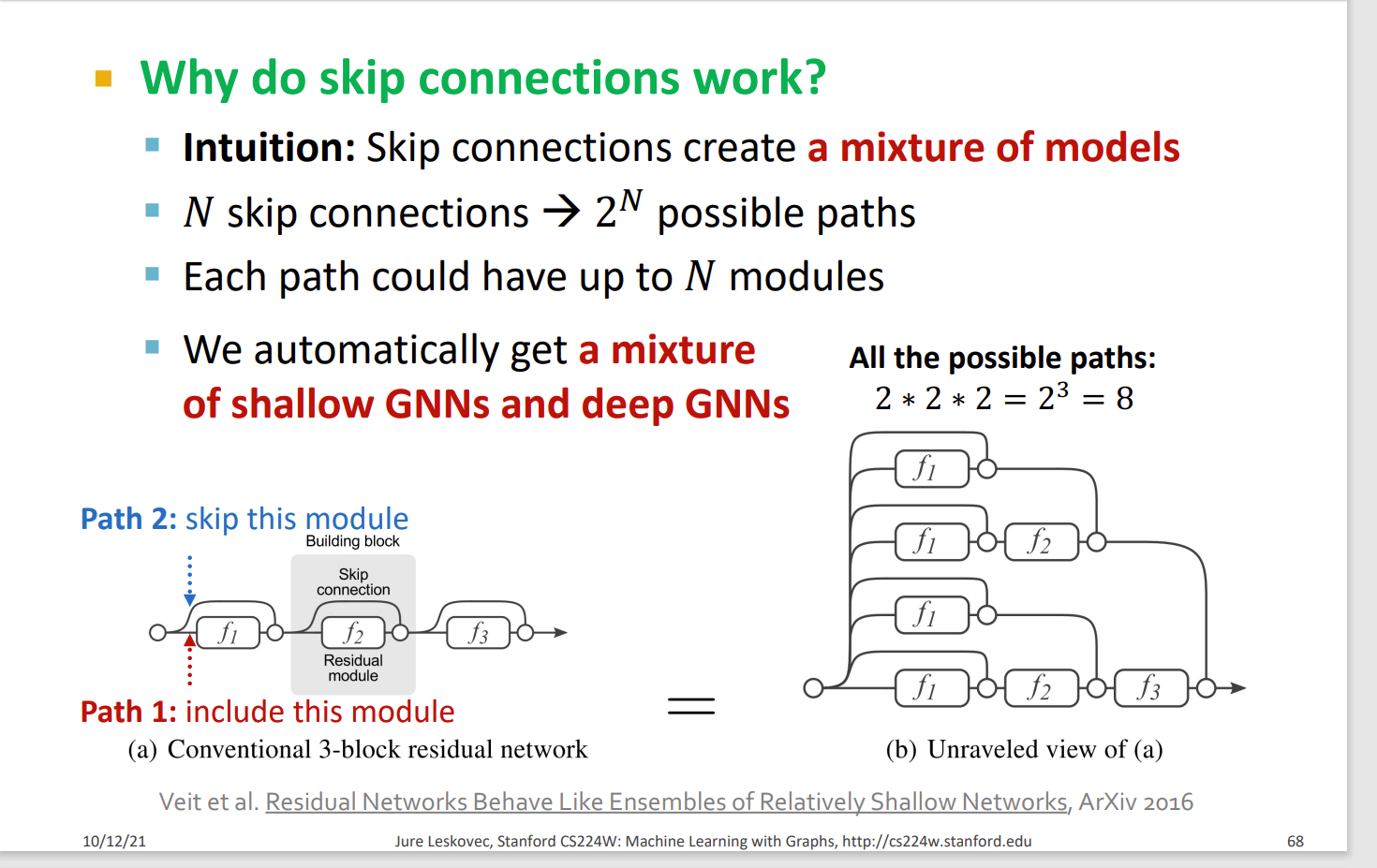
GCN with Skip Connections
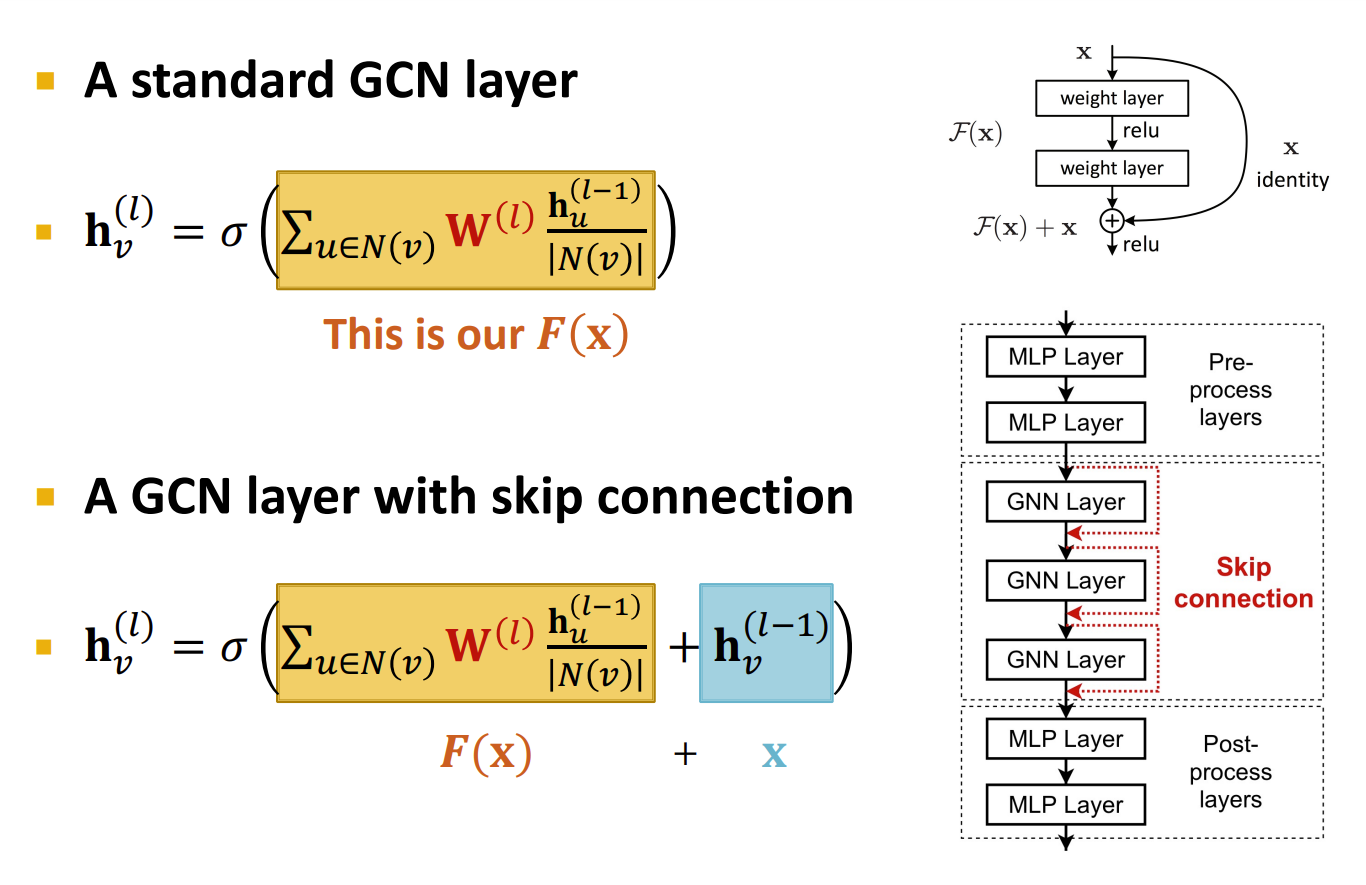
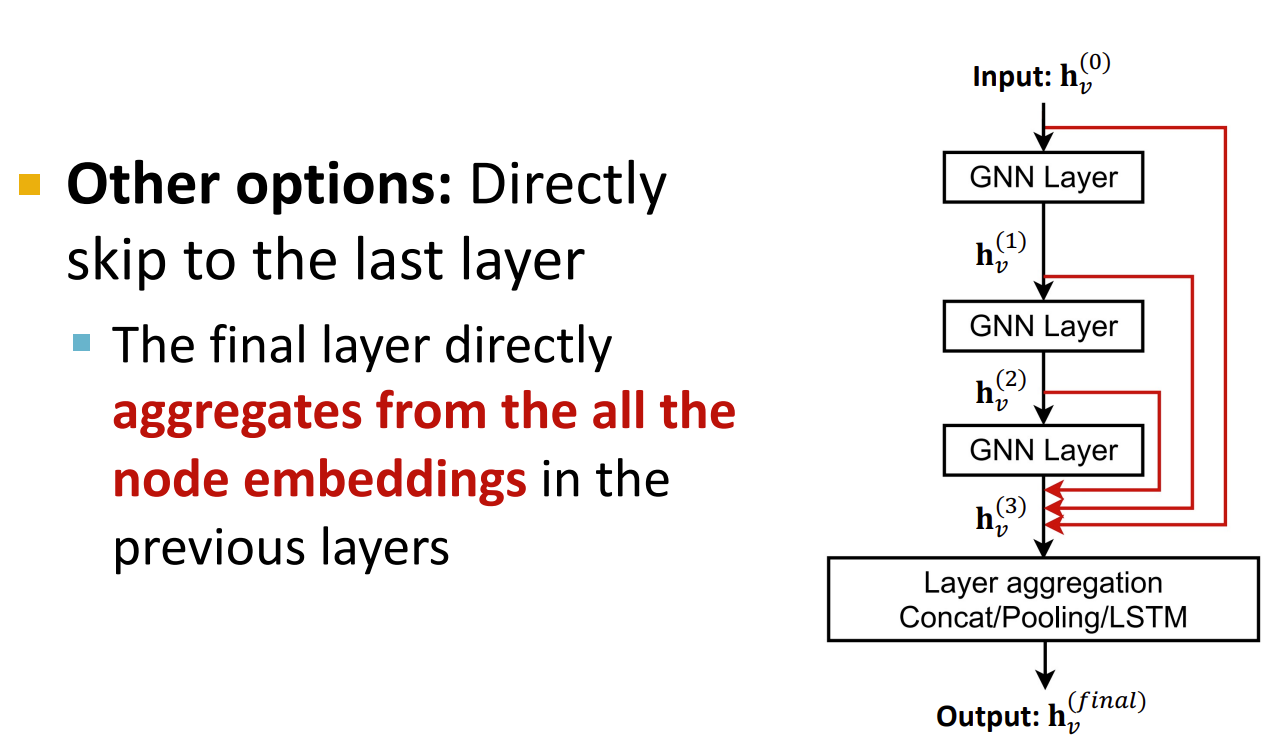
另外一种方法:直接让每一层跳到最后一层