变形金刚
大部分图片来自
Photation is All You Need
在说变形金刚之前,我们考虑几个问题
LSTM,GRU的缺点有哪些,它有什么可取之处
很显然, LSTM , GRU 以及普通的 RNN 模型严重依赖上一个时间点的结果,这限制了模型的并行性。此外,对于超长文本,即使是 GRU LSTM 表现也不够好。
为什么要利用 CNN 替代 RNN ?
CNN的缺点有哪些 ?
Transformer
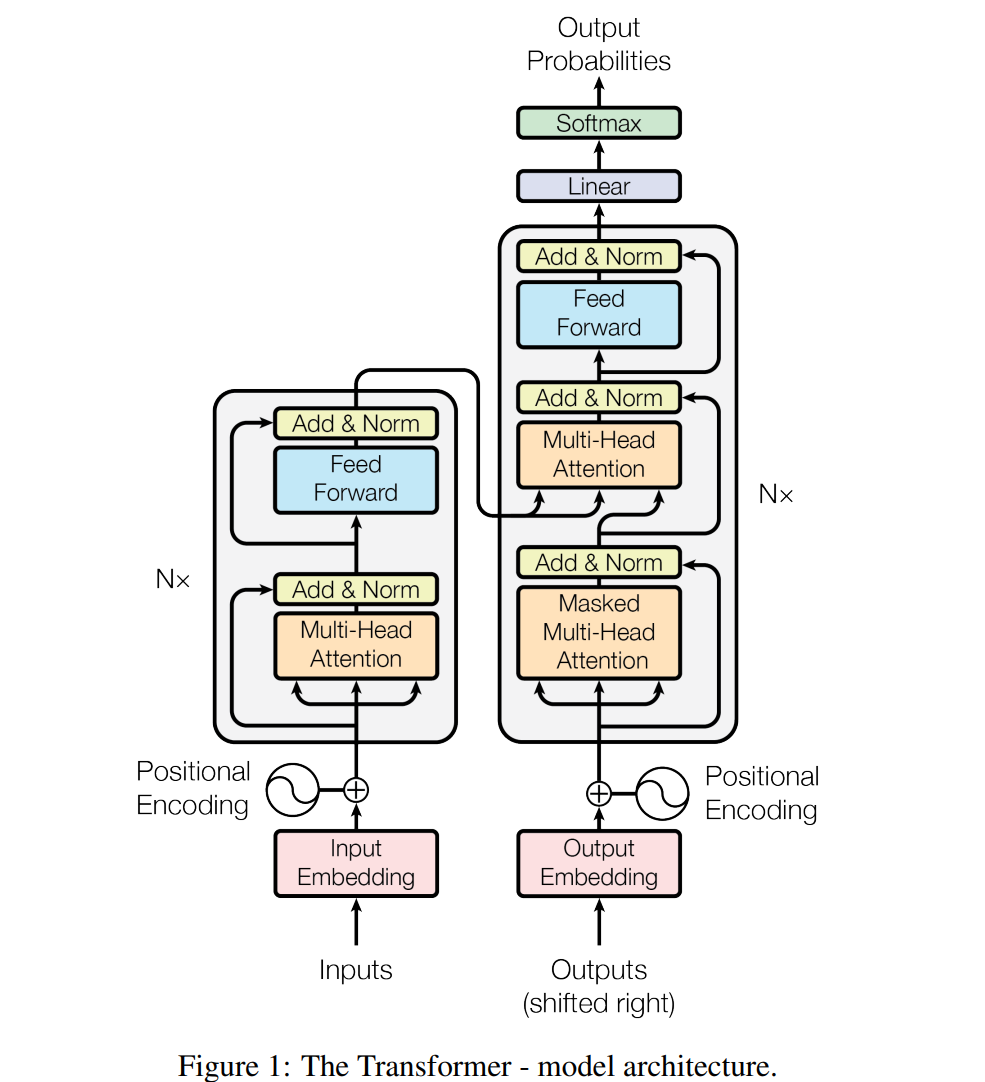
Transformer 是一个 enc-dec 的结构
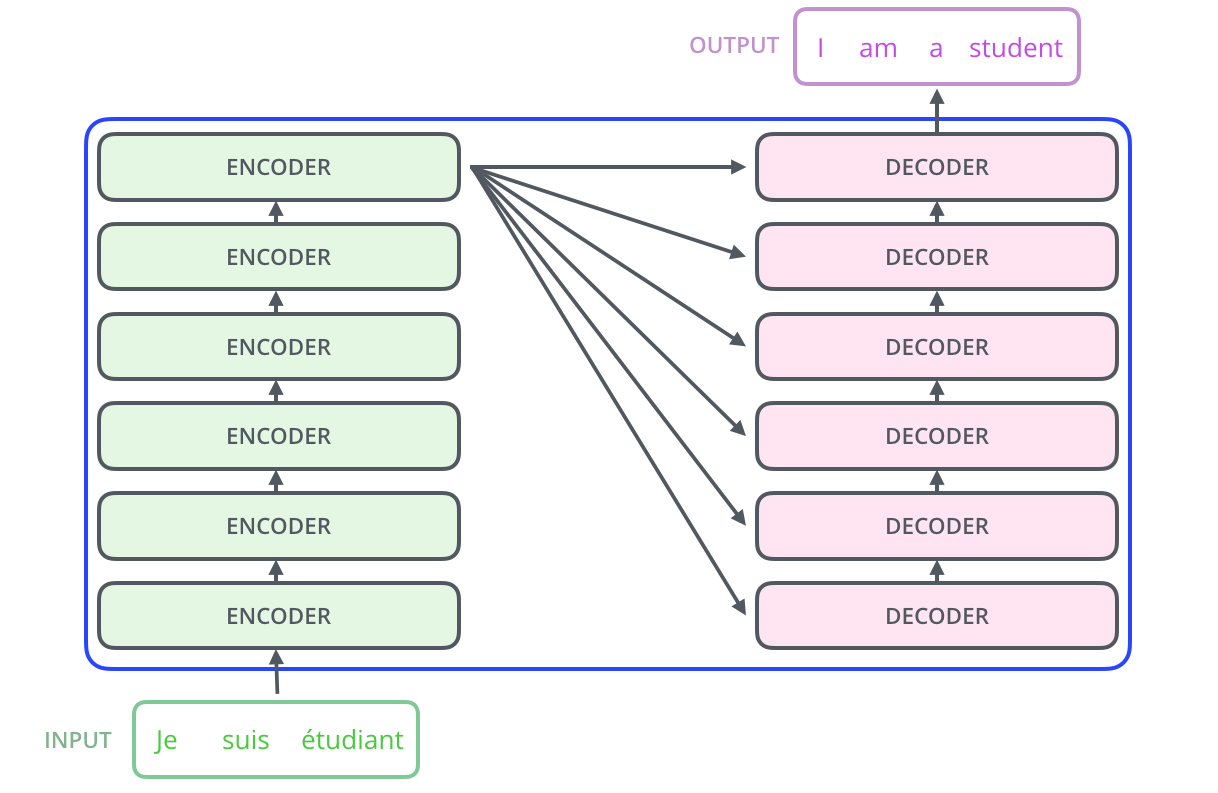
enc 和 dec 具体如下
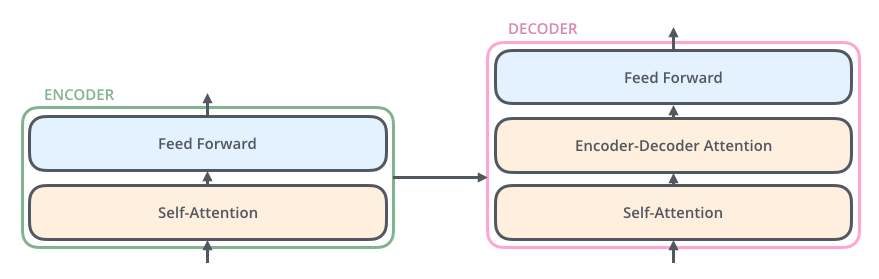
输入数据编码
Word2Vec
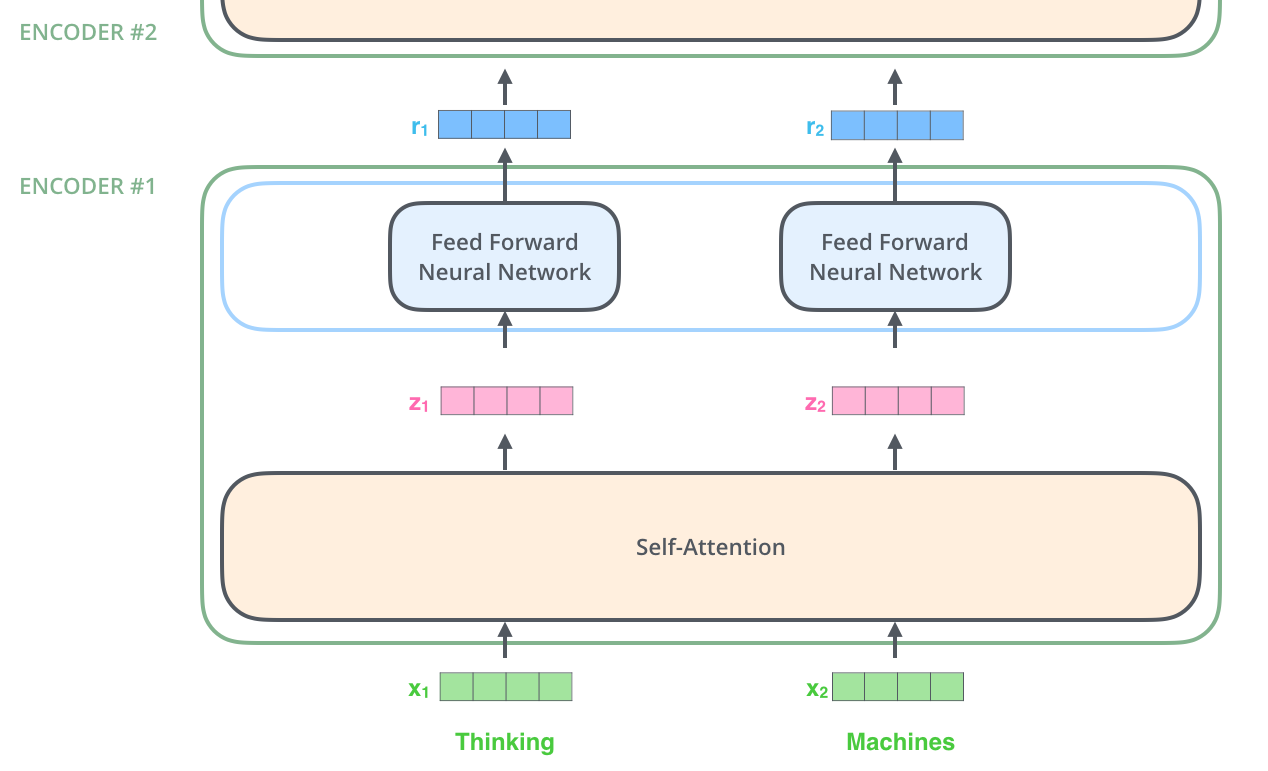
除了第一层的词向量是 Word2Vec 其他的都是上一个 enc 的输出
Self-Attention

我们想用 Self Attention 找到句子中每个词和哪个有关联,例如上面这句话,我们要做的就是找到it 指代的是
在 selfattention 中 ,每个单词有三个不同的向量 Q K V ,它们是嵌入向量乘上三个不同的权重矩阵得到的。
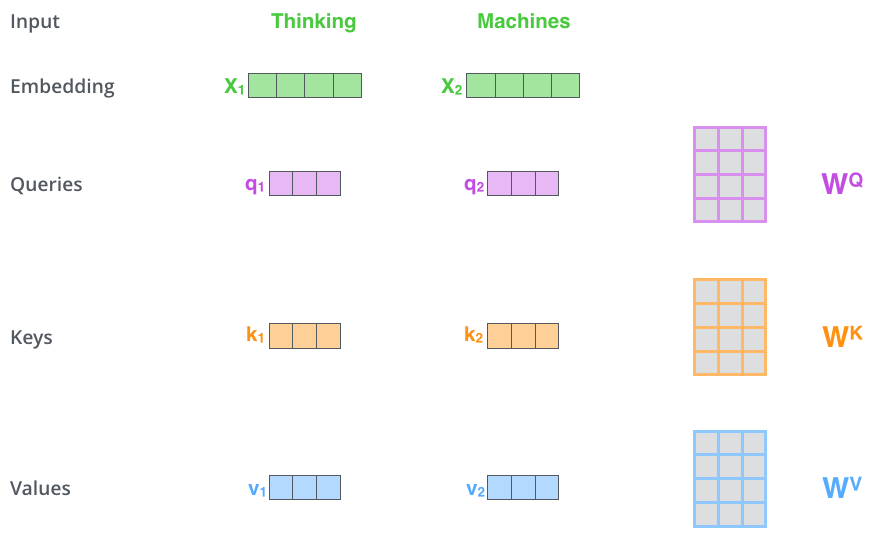
计算流程如下
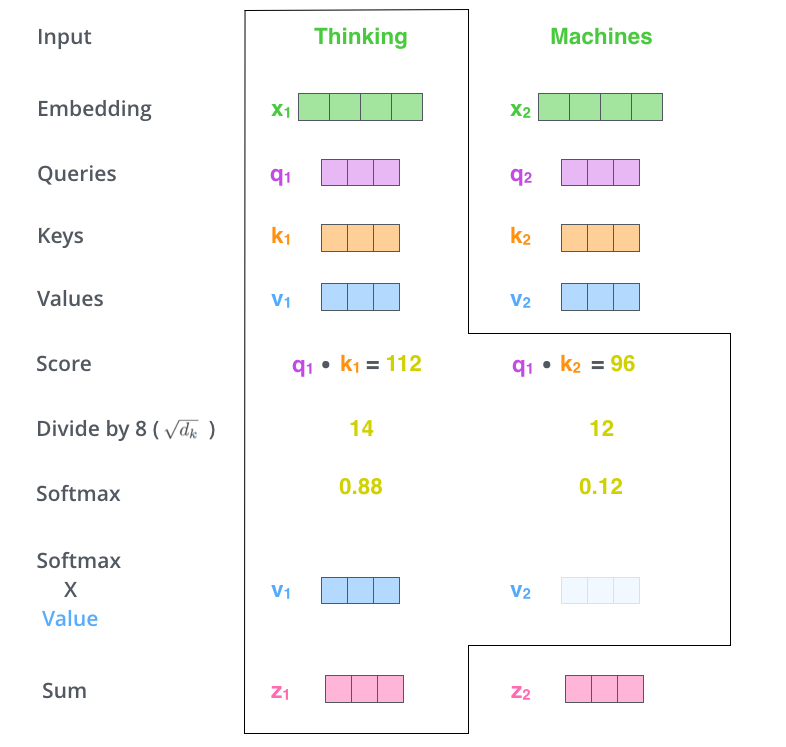
换句话说,最后得到的效果是这样的
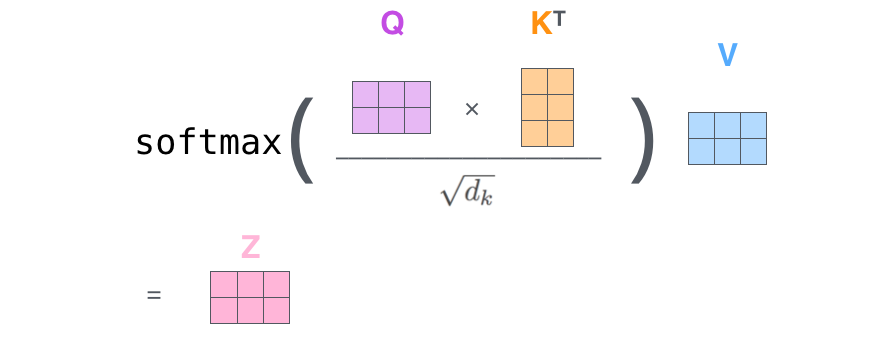
这里需要进一步的解释:
1.在矩阵计算中,点积可以用来计算两个矩阵相似度,因此使用 来计算矩阵的相似度,然后加权匹配输出,权重恰好是这个相似度
2.但是此时存在的一个问题是梯度不一定稳定,通过玄学我们得到了把最后得分除 也就是 k 向量维度的根号可以让梯度更稳定的结论
3.但是权重还没有归一化,我们还得采用一个 函数归一化
4.此时我们得到的值再与 乘,这里需要注意到 得到 (放张图说明一下,图源见水印)

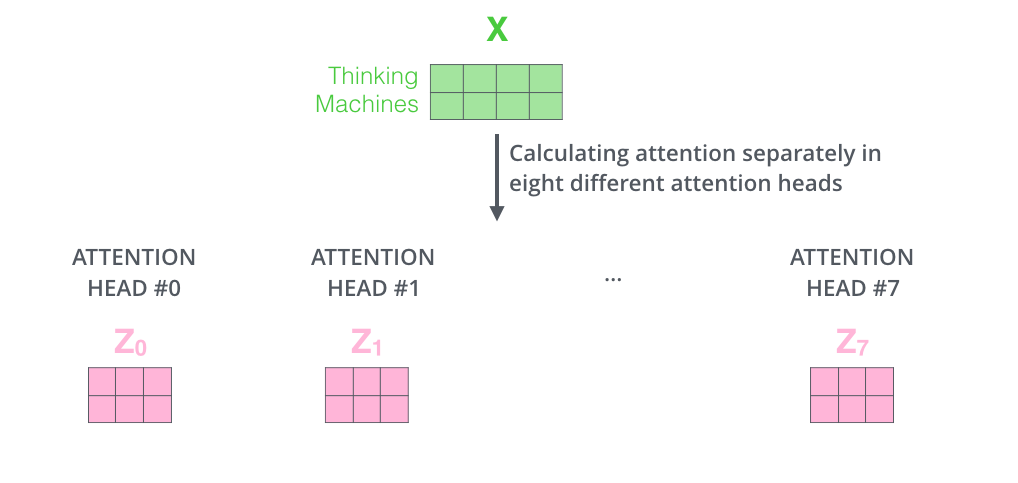
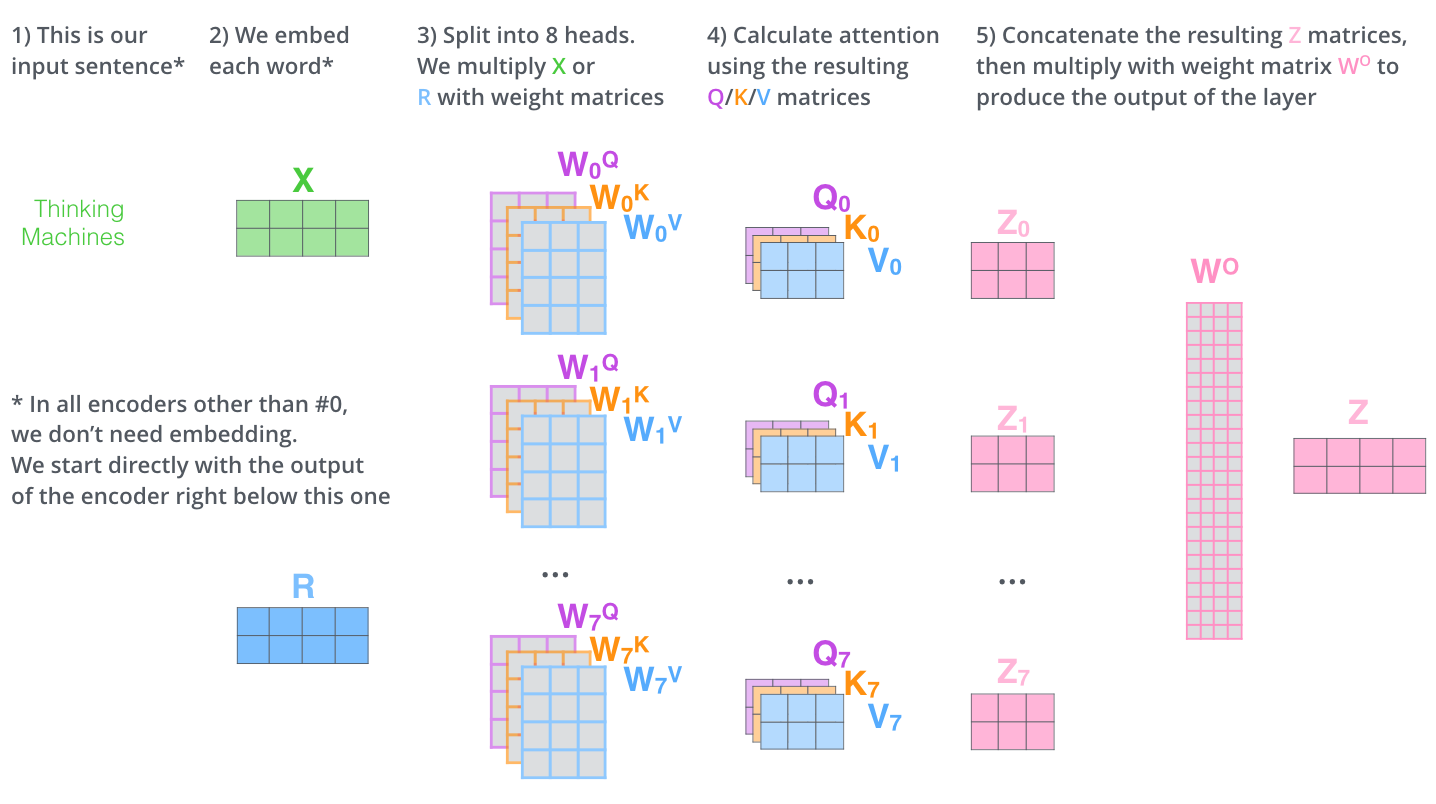
Multi-Head Attention
多头注意力
这相当于多个不同的 self-attention 的集合,例如在 的情况,我们可以得到 个特征矩阵,把它拼接后再来一个全连接层可以得到最后的输出
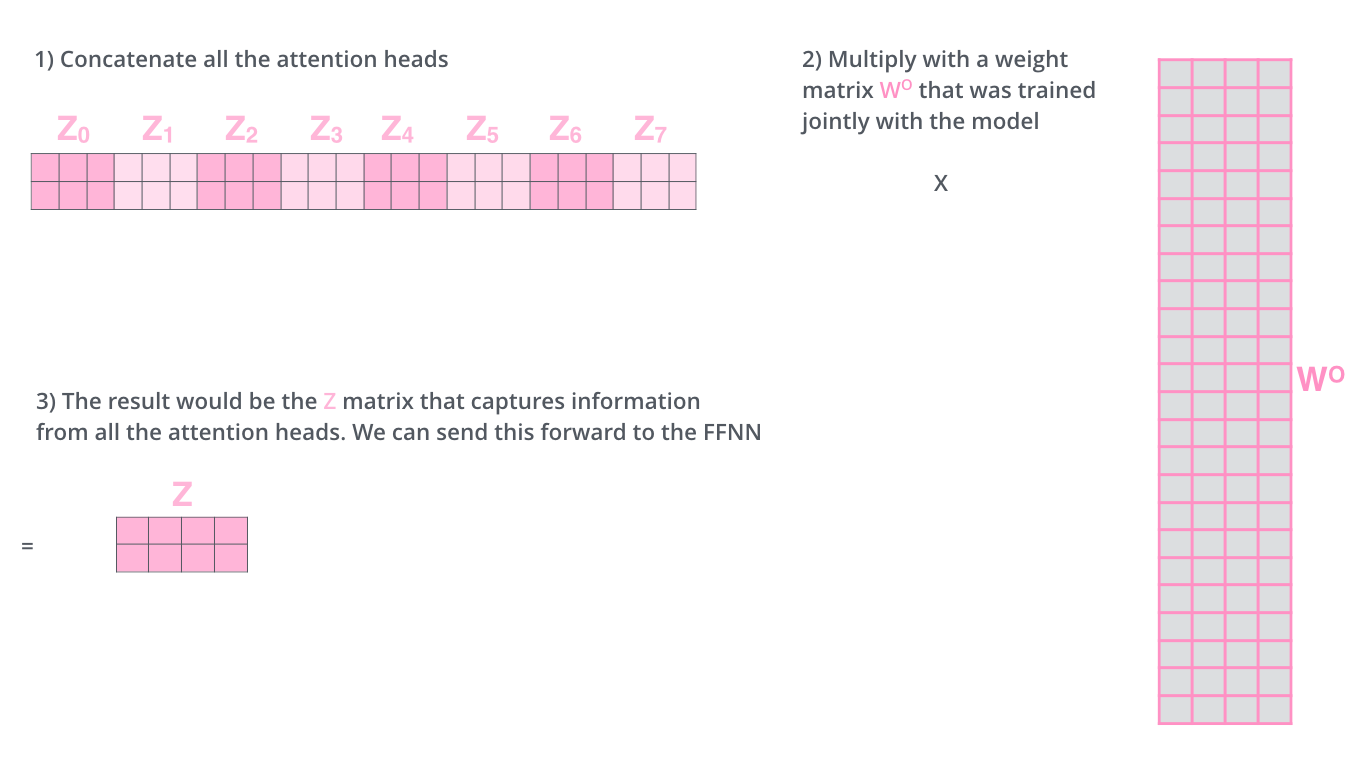
在 enc-dec attention 中, 解码过程是由顺序的,我们没有办法看到之后的解码结果,这种情况下就称为 masked multi-head attention
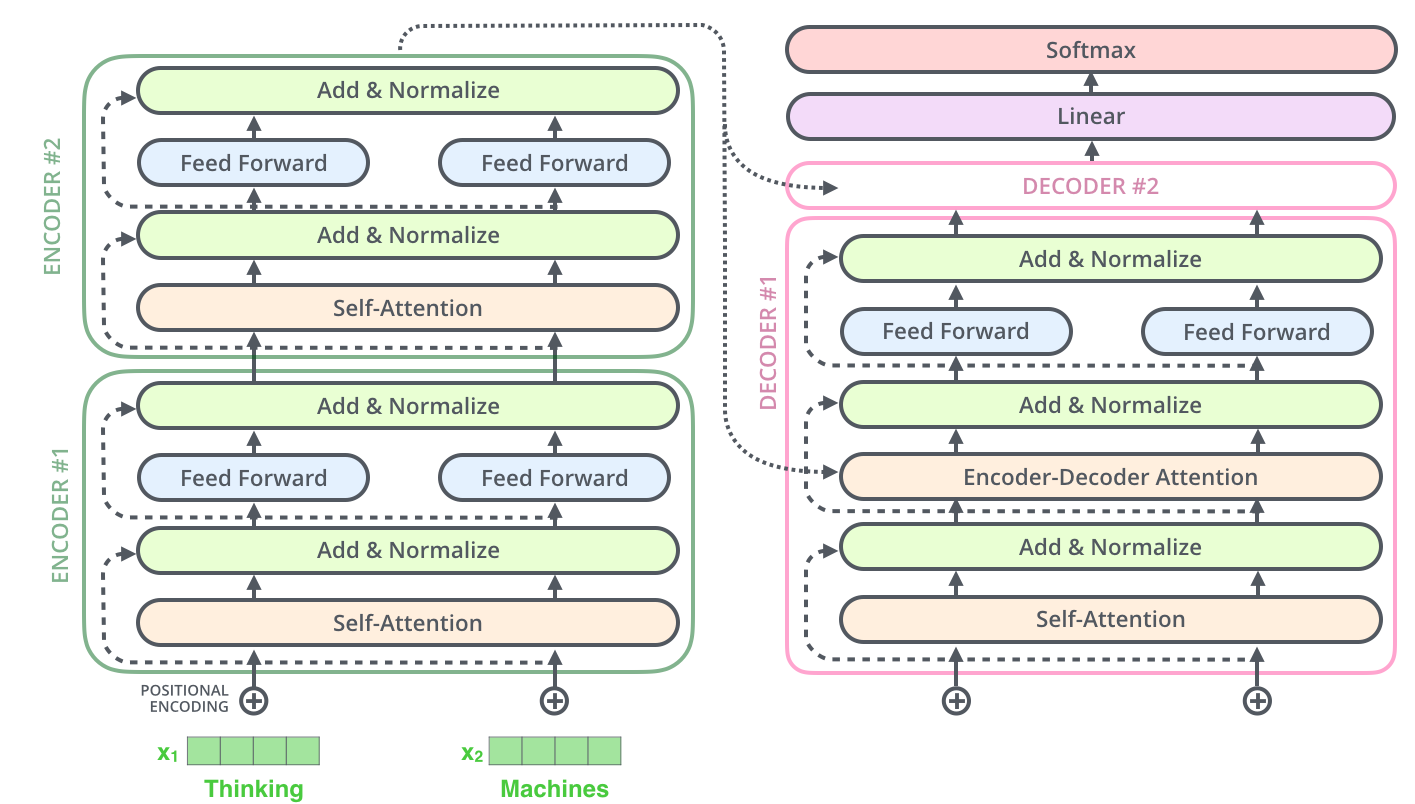
以上是一个完整的 enc-dec 网络,我们可以堆叠这样的网络
现在您应该能看懂变形金刚了
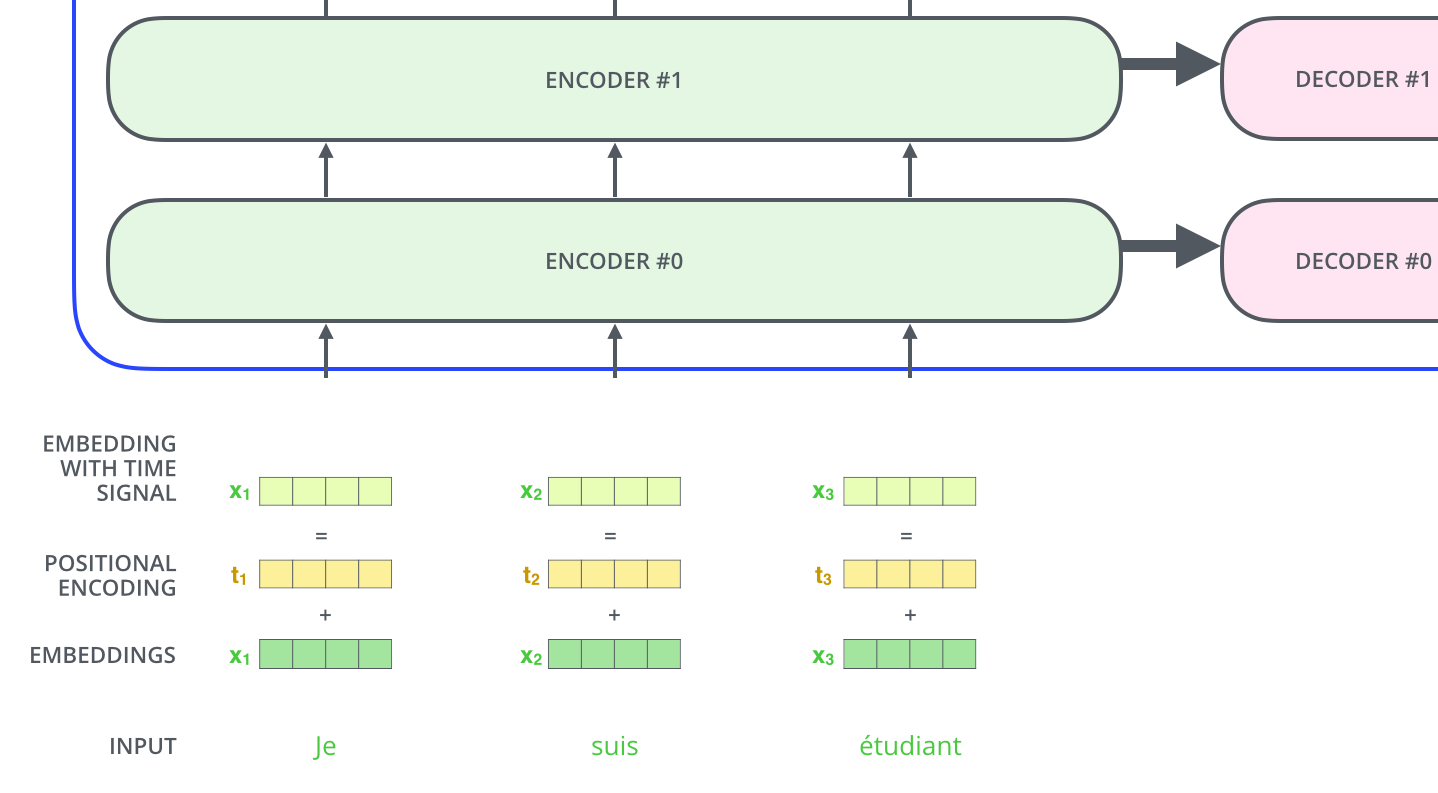
Position Embedding
通过常识我们可以得到,汉字的序顺并不影响读阅,但是存在这种问题
Mcggvc 吊打 scmmm
如果我们机器学习把 Mcggvc 吊打 scmmm 和 scmmm 吊打 Mcggvc 混为一谈,那就说明报道出了偏差,是要负责任的。
我们可以让输入的 embedding 加一层时序的编码
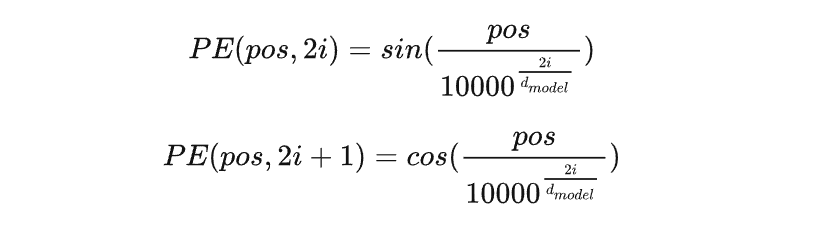
感性理解一下
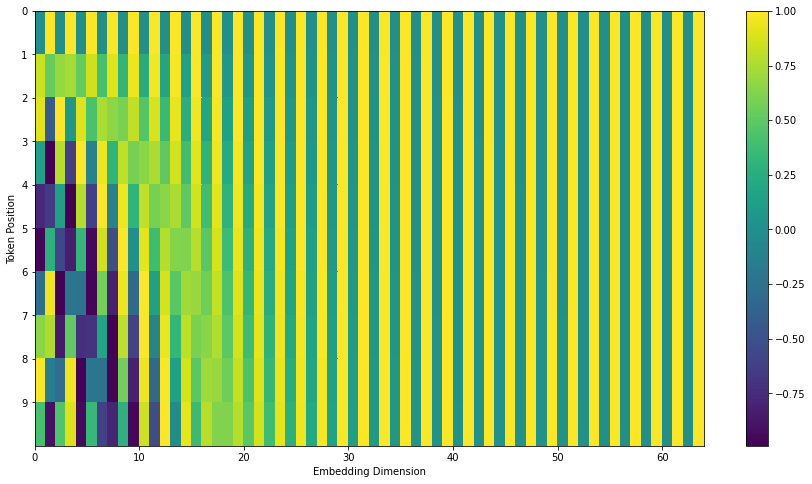
我也不知道为什么会用这个函数,可以感性理解一下的就是 也就是能捕捉到单词之间的相对位置(我没懂这一块)
Why LayerNormalization
这个和 BN 一样都是减去均值除以方差,但是由于 transformer 我们输入的是一个句子 ,每个句子有很多个单词 ,每个单词都有一个向量表示,它是三维的
LN 不需要全局的均值和方差,因为这是对每一个样本(一句话)来做的。 考虑到句子长度不同,BN算出来的均值和方差抖动很大,所以此时只能用LN





