cs224w-4-PageRank
Link Analysis: PageRank (Graph as Matrix)
由于每章都有很多芝士点,所以我打算改成一章一章来了
前言
用邻接矩阵的形式来看这张图
目标
定义图上节点的重要性,比如互联网上每个网站的重要性(node:网站,edge=hyperlink,directed)
有些情况暂时不需要考虑:
1.pages created on the fly 大概是随手生成的
2.dark matter 有密码这样的
应用场景
网页内,网页间,引用,百科等。
PageRank
Link Analysis approaches
主要是三种 PageRank , Personalized PageRank (PPR) 和 Random Walk with Restarts
方法就是把超链接视为权重,如果自己被重要的网站挂了重要的网站(权重)有一个指向该网站的超链接,那显然这个网站权重也很高,我们通过这个方式计算每个网站的权重,显然这是一个递归问题。
计算权重
假设第 点权重为 , 度数为 (出度) ,我们可以让 连接的每一个节点的权重加上
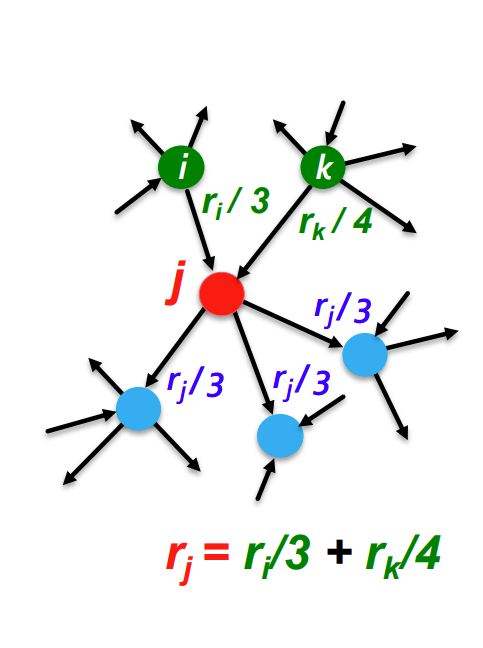
换句话说,我们想要这样迭代
显然,这样的转移可以写成一个矩阵的形式。
聪明的你一定想到了高斯消元,然后经典发问:我这个跑了一天怎么还没跑出来啊
现在我们定义一个向量 ,其中 表示 的重要性,并且满足
我们在构造一个矩阵,使得
此时转移可以写为 ,这是一个迭代过程,假设现在为 时刻,有
这个形式形如
如果 经过多次迭代后,满足式子 那么我们就没必要继续算了
实际上我们可以认为当 时,收敛(convergence)
幂迭代(power iterations)
首先初始化,
然后迭代, 直到收敛
一般来说,到50次左右就可差不多了
特殊情况
然而,这么做的话,有两个特殊情况无法解决
1.死点 dead ends 出度为0的点,这样之后整张图权重会变成0
2.Spider traps,all out-links are within the group,大概的意思就是说出现了一个scc,然后这个scc吃满了所有的重要性。
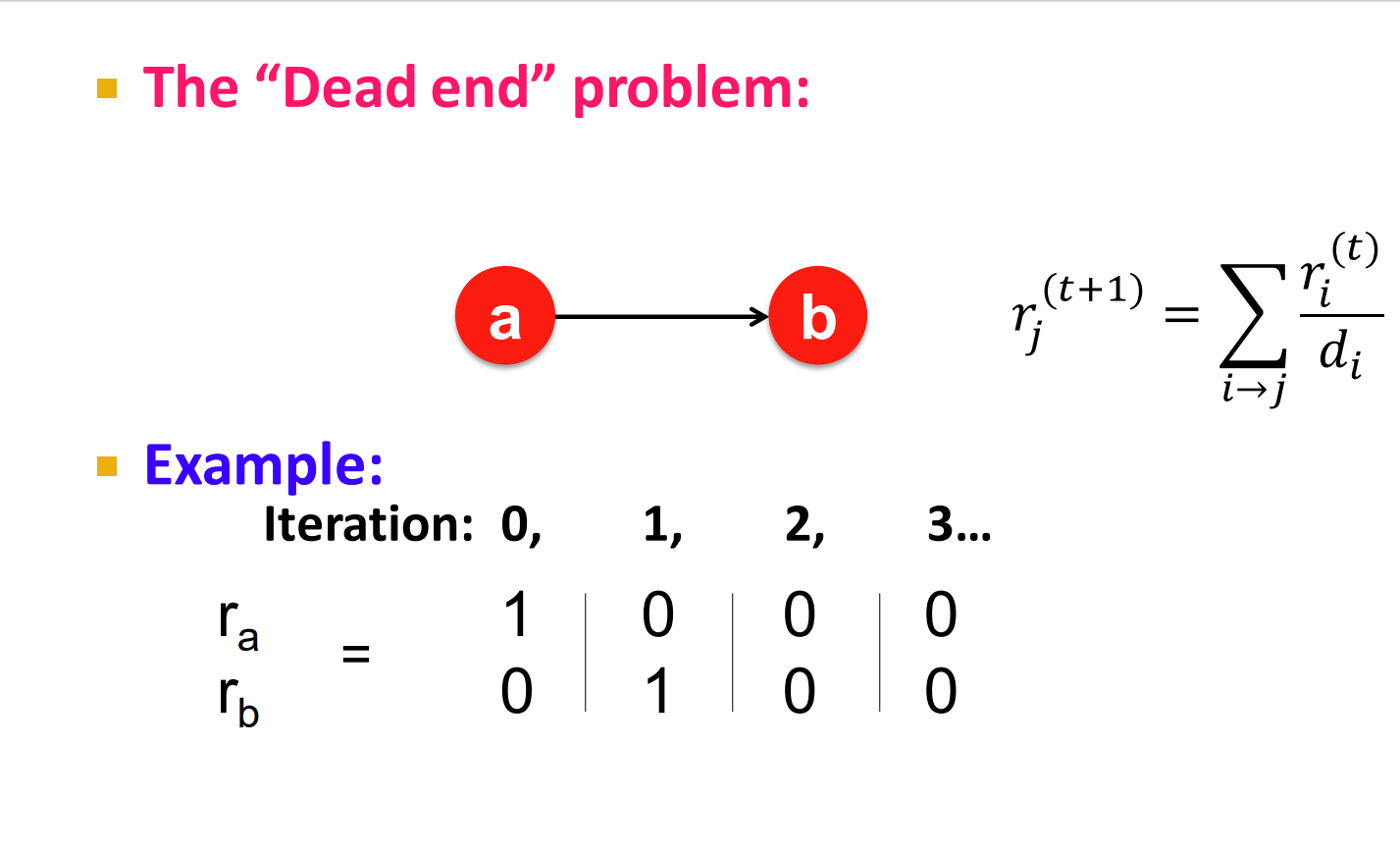
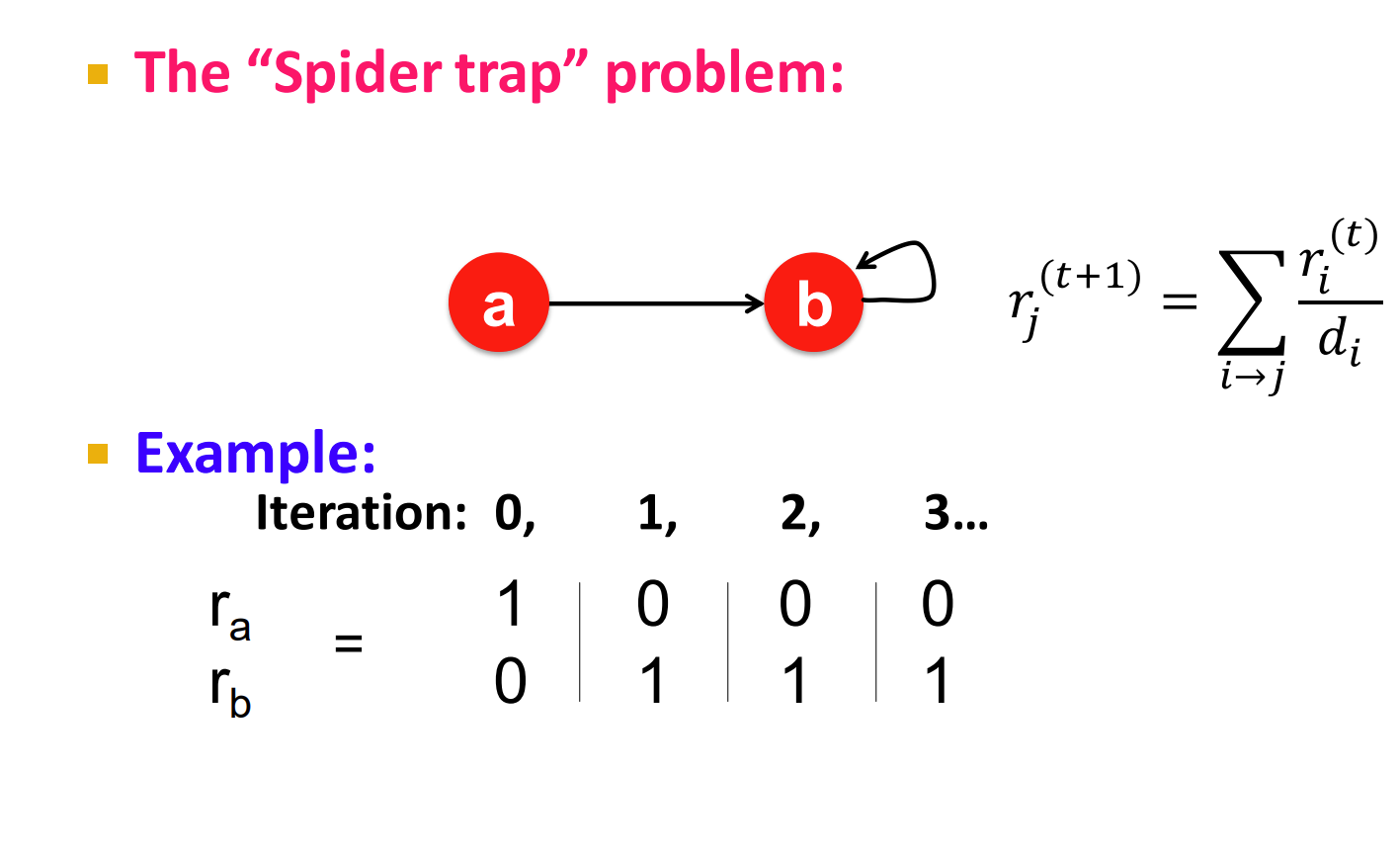
解决这个问题
此时我们跳不出去是吧,我们设定一个概率 ,到这个点时将会有 概率继续走,否则 概率随机跳,一般来说 (平均 5 到 10 步就跳出去)
此时我们迭代的公式改写成为
换句话说,我们设某个大公司 G 提出额矩阵为
公式就变成
应用举例:推荐系统
给你一个二分图,两边分别是用户和关系。例如有以下情况:
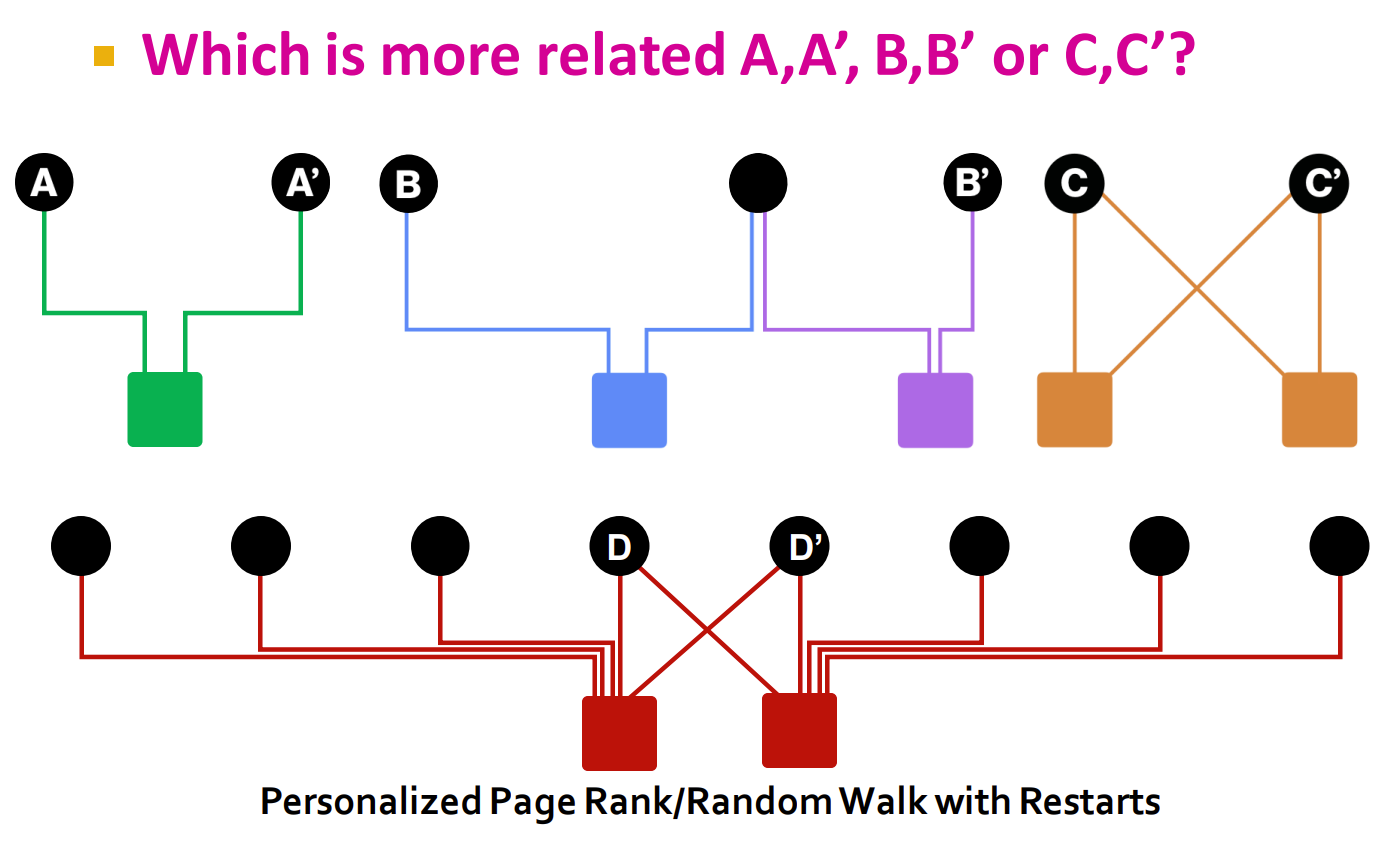
现在的目标就是让你确定与点集 相关性最大的节点
我们采用PageRank来处理,但是我们做一下更改,把随机传送的节点仅限于点集
伪代码如图:

需要注意到此时
最后 最高的节点就是相似度最高的节点。
这是PageRank及其同分异构体

矩阵分解
如果两节点相连,我们就认为相似,此时我们假设一个嵌入矩阵 ,满足 , 为图矩阵,换句话说 ,显然,这个方法没有降低复杂度。
我们花一种思路,最小化 距离 ,即元素差的平方和, 即 ,实际上用 也行
DeepWalk
不想打公式。
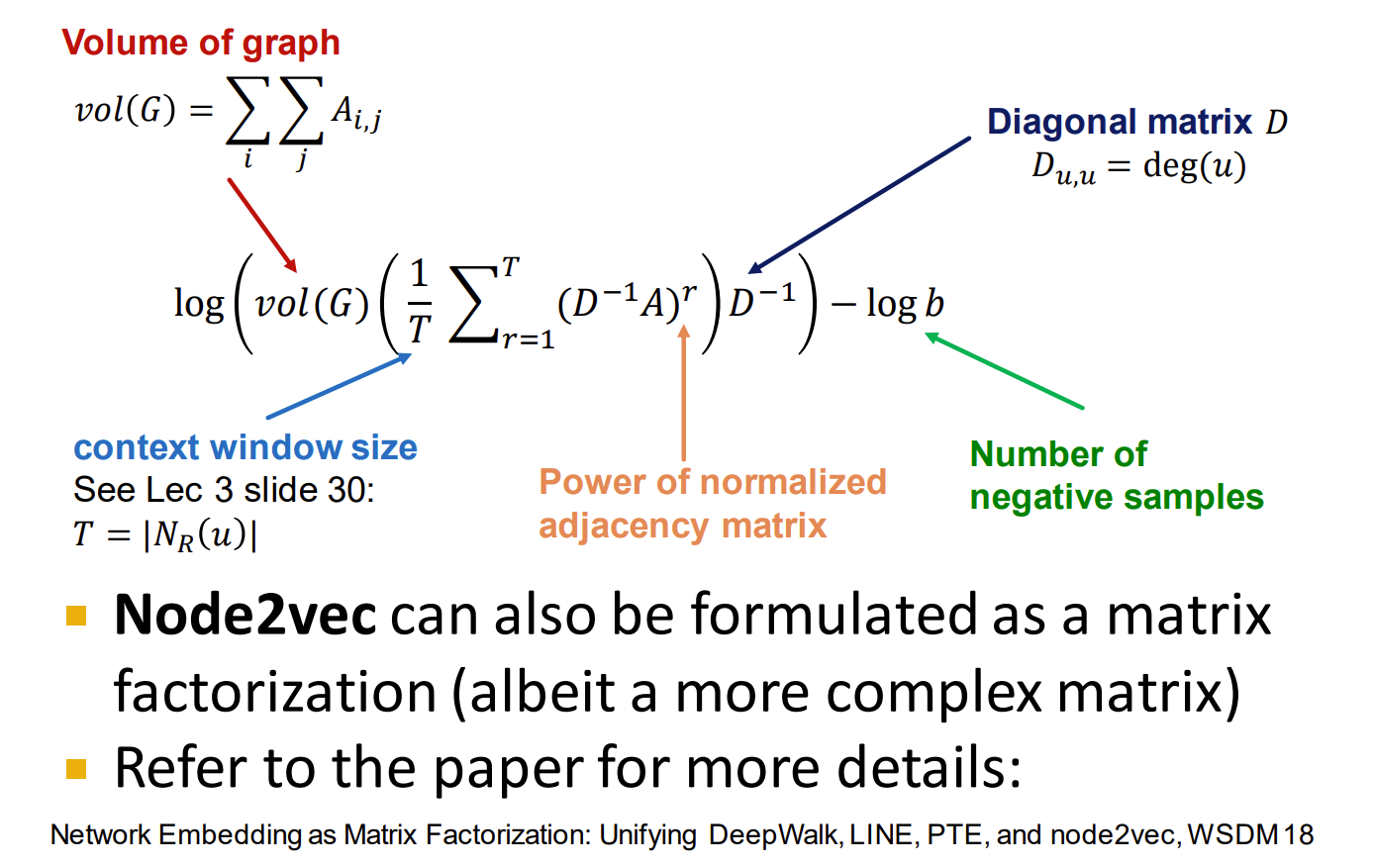
缺点
没法在线,每次加入后得重新计算embedding
结构相似,例如同样是 ,embedding 后面结果不一样
Cannot utilize node, edge and graph features (没法利用这些东西的特征?)





